
ProtoSound: A Personalized and Scalable Sound Recognition System for Deaf and Hard of Hearing Users
ProtoSound: A Personalized and Scalable Sound Recognition System for Deaf and Hard of Hearing Users
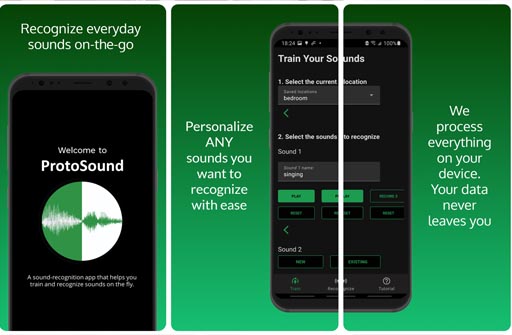
Recent advances have enabled automatic sound recognition systems for deaf and hard of hearing (DHH) users on mobile devices. However, these tools use pre-trained, generic sound recognition models, which do not meet the diverse needs of DHH users. We introduce ProtoSound, an interactive system for customizing sound recognition models by recording a few examples, thereby enabling personalized and fine-grained categories. ProtoSound is motivated by prior work examining sound awareness needs of DHH people and by a survey we conducted with 472 DHH participants. To evaluate ProtoSound, we characterized performance on two real-world sound datasets, showing significant improvement over state-of-the-art (e.g., +9.7% accuracy on the first dataset). We then deployed ProtoSound's end-user training and real-time recognition through a mobile application and recruited 19 hearing participants who listened to the real-world sounds and rated the accuracy across 56 locations (e.g., homes, restaurants, parks). Results show that ProtoSound personalized the model on-device in real-time and accurately learned sounds across diverse acoustic contexts. We close by discussing open challenges in personalizable sound recognition, including the need for better recording interfaces and algorithmic improvements.
Publications
ProtoSound: A Personalized and Scalable Sound Recognition System for Deaf and Hard of Hearing Users
Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems (CHI), 2022.
Keywords: accessibility, deaf, Deaf, hard of hearing, sound awareness